
よく使うEXCELの関数集3(文字列の操作)
文字列操作の関数
前回は日付にかかわる関数についてご紹介しました。
今回は効率化につながる関数の第三弾として文字列操作にかかわる関数をご紹介します。
文字列の操作を覚えると応用の範囲格段にが広がります。
この後にご紹介する論理関数では、文字列操作と組み合わせてをよく使いますのでしっかり覚えておきましょう。
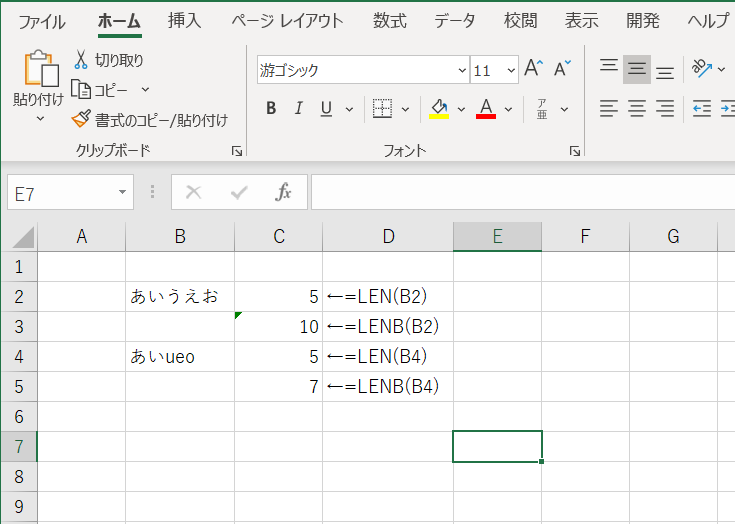
文字列の長さを求める(LEN、LENB)
LEN : 文字数を求める
使用例 : =LEN(B2) 対象セルの文字数を表示します。
LENB : バイト数を求める
使用例 : =LENB(B2) 対象セルのバイト数を表示します。
※上記2つの関数両方とも()内には直接文字や数字を記載することもできます。
例:LEN(”あいうえお”)、文字の際には””で文字を囲みます。数字の場合はLEN(12345)のように
そのまま記載しても問題ありません。
捕捉 : 日本語の文字は2バイトで構成されており、英数字は1バイトで構成されています。
文字列に半角が含まれているかどうかの検査や、表示サイズに合わせるために
制限したりする場合に使用します。
また、(B2&B4)のように&を使って文字列を連結して数を表示させることもできます。
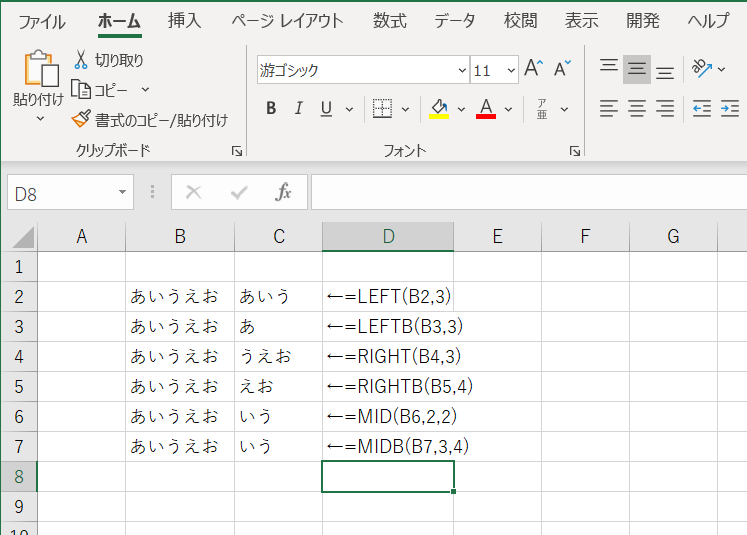
文字列を抽出する(LEFT、LEFTB、RIGHT、RIGHTB、MID、MIDB)
LEFT : 左から指定した文字数分を抽出する
使用方法 : (抽出したい文字列が入ったセル,抽出したい文字数)
使用例 : =LEFT(B2,3)
LEFTB : 左から指定したバイト数分を抽出する
使用方法 : (抽出したい文字列が入ったセル, 抽出したいバイト数)
使用例 : =LEFTB(B3,3)
RIGHT : 右から指定した文字数分を抽出する
使用方法 : (抽出したい文字列が入ったセル, 抽出したい文字数)
使用例 : =RIGHT(B4,3)
RIGHTB : 右から指定したバイト数分を抽出する
使用方法 : (抽出したい文字列が入ったセル, 抽出したいバイト数)
使用例 : =RIGHTB(B5,4)
MID : 指定した位置から指定した文字数分を抽出する
使用方法 : (抽出したい文字列が入ったセル, 抽出開始文字位置,抽出したい文字数)
使用例 : =MID(B6,2,2)
MIDB : 指定した位置から指定したバイト数分を抽出する
使用方法 : (抽出したい文字列が入ったセル, 抽出開始バイト位置, 抽出したい文字数)
使用例 : =MIDB(B7,3,4)
応用編(フルパスの文字列からファイル名を抜き出す)
=RIGHT(B2,LEN(B2)-FIND(“”,SUBSTITUTE(B2,”\”,””,LEN(B2)-LEN(SUBSTITUTE(B2,”\”,””)))))
↑こんな関数を記載すると
c:\windows\temp\excel.txtc:\windows\temp\excel.txt
↑上記のような文字列が格納されているB2セルからファイル名「excel.txt」だけを取り出すことが可能です。
簡単に説明するとまず、SUBSTITUTEという関数でB2セルに入っている\を除いた文字数をLENで出し、
別のLENで\が含まれた文字数から引くことで\の数を求めています。
FINDで\の数分の値を与えてあげることによって最後の\のある文字位置を求めます。
その文字位置を全体の文字数から引くことによってファイル名の文字数が求められます。
最後に右からそのファイル名分の長さを抜き出すことによってファイル名を取り出すことができます。
このように応用次第で便利なことがたくさんできますので、少しずつお伝えしていきます。
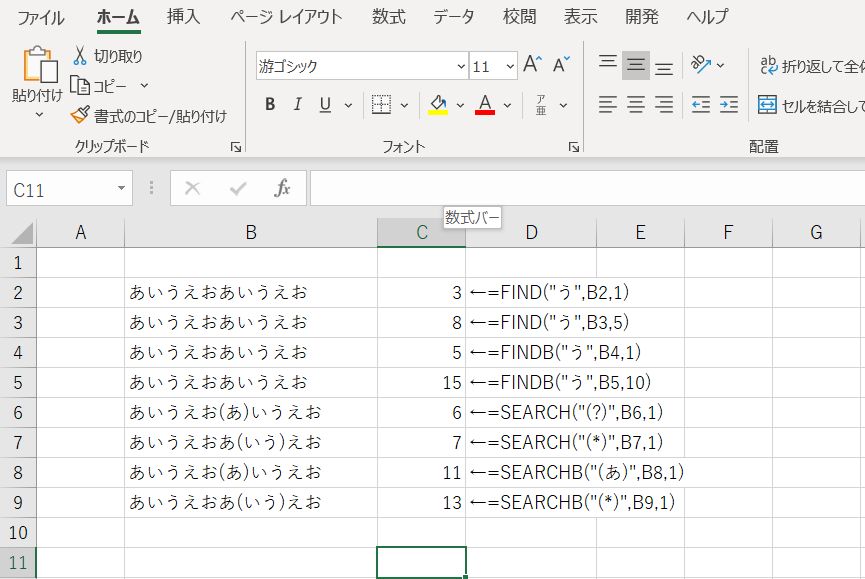
文字を検索する(FIND、FINDB、SEARCH、SEARCHB)
FIND : 先頭から指定した文字を検索しその文字位置を表示する
使用方法 : (検索したい文字列, 抽出したいセルや文字列, 検索を開始する位置)
使用例 : =FIND(“う”,B2,1)
FINDB : 先頭から指定した文字を検索しそのバイト位置を表示する
使用方法 : (検索したい文字列, 抽出したいセルや文字列, 抽出開始バイト位置)
使用例 : =FINDB(“う”,B4,1)
SEARCH : 先頭から指定した文字を検索しその文字位置を表示する
使用方法 : (検索したい文字列, 抽出したいセルや文字列, 検索を開始する位置)
使用例 : =SEARCH(“(?)”,B6,1)
SEARCHB : 先頭から指定した文字を検索しそのバイト位置を表示する
使用方法 : (検索したい文字列, 抽出したいセルや文字列, 抽出開始バイト位置)
使用例 : =SEARCHB(“(*)”,B9,1)
FINDとSEARCHは同じような関数ですが、以下のような違いがありますのでご注意ください。
FIND : 大文字と小文字を区別する、ワイルドカード*や?が使えない
SEARCH : 大文字と小文字を区別しない、ワイルドカード*や?が使える
★Tips★ワイルドカードとは
特定の文字を指定せずパターンにマッチするものを指定する場合に使います。
「*」というワイルドカードはこの「*」の部分にはどんな文字でも何文字でもよいというものです。
例えば、検索条件で
い*う
とした場合に、「い」と「う」の間には何が入ってもよいという事になり、
あい1うえお、あい123うえおでも検索にマッチします。
「?」というワイルドカードは「?」の部分はどんな文字でもよいが、必ず?の数分の文字というものです。
例えば、検索条件で
い?う
とした場合に、「い」と「う」の間には何が入ってもよいが1文字のみという事になり、
あい1うえお、は検索にマッチしますが、あい123うえおででは検索にマッチしません。
あい123うえおを検索でマッチさせるためには、い???うという検索条件にします。
いかがでしたでしょうか?
文字列操作の関数は色々応用ができるので、覚えておくと非常に便利で省力化につながります。
文字列の操作にはまだいくつか便利な関数がありますが、あまり長くなると疲れてしまうと思うので
次回に回そうと思います。
文字列操作の関数の次はいよいよ論理関数に入っていきます。
この論理関数が使えるようになると、ロジカルシンキングが身に付き、ついにプログラマーの仲間入りになってきます。
しっかり覚えていきましょう!
では、次回をお楽しみに。
